[AI Times] ‘클로드 미소스’를 파이토치로 재현한 오픈소스 프로젝트 ‘오픈미소스’ 등장
(사진=X, Kye Gomez)
앤트로픽이 개발한 차세대 AI 모델 ‘클로드 미소스(Claude Mythos)’의 구조를 둘러싼 궁금증이 이어지는 가운데, 이를 이론적으로 재구성하려는 오픈소스 프로젝트 ‘오픈미소스(OpenMythos)’가 공개돼 주목받고 있다.
카이 고메스 스웜즈(swarms.ai) CEO는 19일(현지시간) ‘클로드 미소스’를 재구성한 오픈소스 프로젝트 ‘오픈미소스’를 깃허브를 통해 공개했다.
이 프로젝트는 실제 모델이나 유출된 코드가 아닌, 순수한 이론적 가설을 바탕으로 구현된 점이 특징이다.
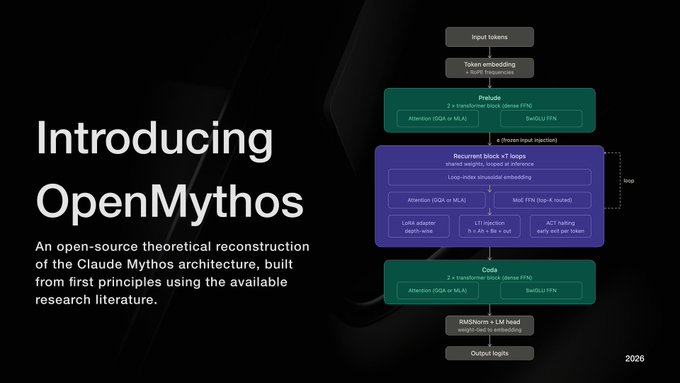
오픈미소스는 파이토치(PyTorch)를 기반으로 구현된 루프형 트랜스포머(Looped Transformer) 구조인 ‘파르카에(Parcae)’를 채택하고 있으며, 여기에 전문가 혼합(MoE) 메커니즘을 결합했다.
이는 동일한 매개변수 블록을 반복적으로 적용하면서도, 단계마다 선택적으로 다른 전문가 네트워크를 활성화하는 방식으로 계산 효율성과 성능 간 균형을 개선하려는 시도다.
기존 ‘GPT’나 ‘라마’ ‘미스트랄’과 같은 전통적인 트랜스포머 모델은 서로 다른 가중치를 가진 레이어를 순차적으로 통과하며 처리 능력을 확장한다.
반면, 오픈미소스가 가정하는 구조는 ‘재귀적 깊이 트랜스포머(RDT·Recurrent-Depth Transforme)’로, 동일한 가중치를 여러 번 반복 적용하는 것이 핵심이다. 즉 모델의 추론 능력은 저장된 파라미터 수가 아니라 추론 시 반복 횟수에 의해 결정된다.
(사진=X, Kye Gomez)
기반이 되는 파르카에(Parcae) 구조는 ‘프렐류드(Prelude)-리커런트(Recurrent)-코다(Coda)’의 3단계로 구성된다. 이 중 핵심은 최대 16회까지 반복되는 리커런트 단계로, 각 반복 단계에서 은닉 상태는 이전 상태와 입력 정보를 함께 반영해 갱신된다. 특히 입력 신호를 반복마다 재주입함으로써, 깊은 반복 과정에서 정보가 왜곡되는 문제를 방지한다.
또 피드포워드 네트워크(FFN) 대신 MoE 레이어를 도입해, 토큰별로 일부 전문가만 선택적으로 활성화하는 희소 연산 구조를 구현했다. 여기에 일부 공통 전문가를 항상 활성화해 범용성을 유지하는 방식도 포함된다. 각 반복 단계마다 서로 다른 전문가 조합이 선택되기 때문에, 동일한 가중치를 사용하면서도 매 반복이 서로 다른 계산 경로를 갖는 것이 특징이다.
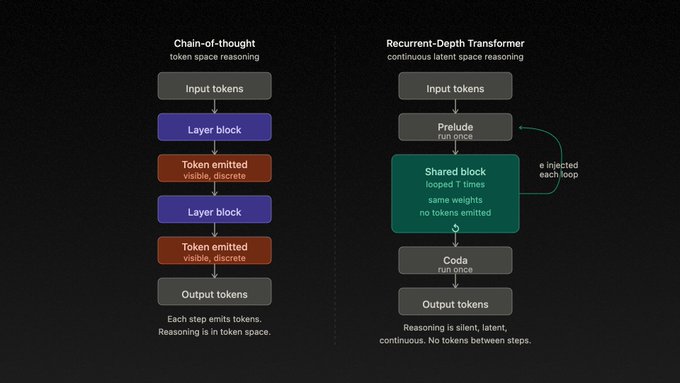
추론 과정도 기존 방식과 차별화된다. 오픈미소스는 중간 단계에서 텍스트를 생성하지 않고, 연속적인 잠재 공간(latent space) 내에서 추론을 수행한다.
이는 사고 사슬(CoT)처럼 중간 결과를 토큰으로 외부화하는 방식과 달리, 내부 벡터 연산만으로 다단계 추론을 진행하는 구조다. 연구에 따르면, 이러한 반복 단계는 각각 CoT의 한 단계와 유사한 역할을 수행하면서 동시에 여러 가능성을 병렬적으로 탐색할 수 있는 장점이 있다.
이 구조의 또 다른 강점은 추론 깊이를 유연하게 확장할 수 있다는 점이다. 일반적인 트랜스포머는 학습 시 경험한 추론 단계 이상으로 확장하기 어렵지만, RDT 구조는 추론 시 반복 횟수를 늘리는 것만으로 더 복잡한 문제를 처리할 수 있다. 즉 어려운 문제에는 더 많은 연산을, 쉬운 문제에는 적은 연산을 할당하는 방식이다.
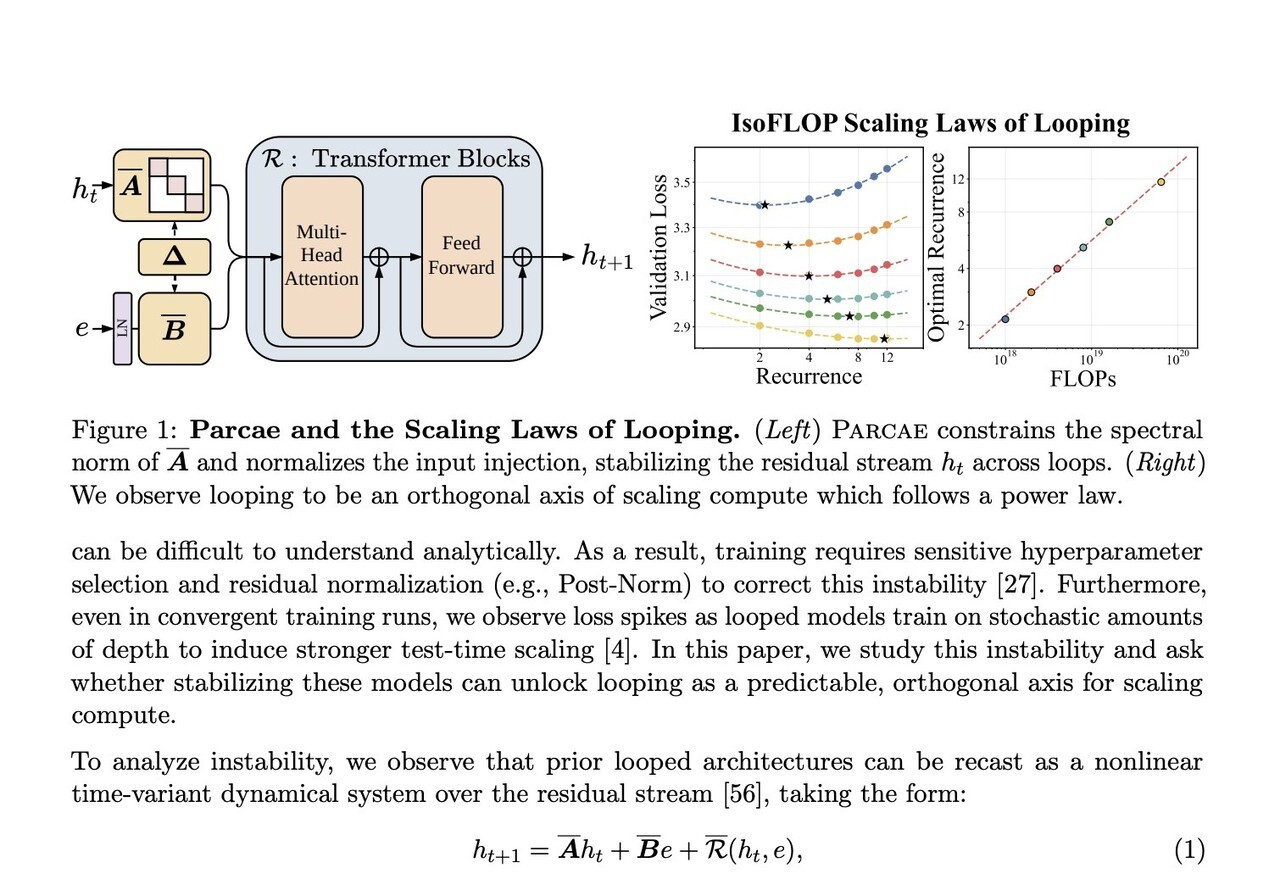
하지만, 반복 구조는 학습 과정에서 불안정성이 큰 문제로 꼽혔다. 반복이 진행될수록 내부 상태가 폭발적으로 증가하거나 손실값이 급등하는 현상이 빈번했기 때문이다.
오픈미소스는 이를 해결하기 위해 파르카에 아키텍처에서 제안된 ‘비선형 시간 불변(Nonlinear Time-Invariant) 동적 시스템’을 도입해 내부 값이 지나치게 커지거나 흔들리지 않도록 했다. 또 ‘과도한 사고(overthinking)’ 문제를 해결하기 위해 토큰별로 필요한 연산량을 자동 조절해 필요한 만큼만 계산하고 자동으로 멈추는 기능을 넣어 효율적으로 동작하도록 만들었다.
여기에 반복 깊이마다 소규모 적응 행렬을 추가하는 깊이별 LoRA(Depth-Wise LoRA) 기법을 도입해, 동일한 가중치 구조에서도 반복 단계별로 미세한 차이를 부여할 수 있도록 했다.
(사진=X, Kye Gomez)
효율성 측면에서도 의미 있는 결과가 제시됐다. 파르카에 연구에 따르면 약 7억7000만개 매개변수를 가진 RDT 모델이 동일 데이터에서 학습된 13억 매개변수 트랜스포머와 유사한 성능을 달성하는 것으로 나타났다. 이는 추론 성능이 단순한 모델 크기보다 반복 깊이에 의해 좌우될 수 있음을 시사한다.
한편, 앤트로픽은 미소스를 공개하며 기술적인 세부 사항은 밝히지 않았다.
따라서 고메스 CEO는 미소스 구조를 추정하기 위해 이제까지 공개된 전문가들의 분석과 관련 자료를 근거로 댔다. 또 “순환 트랜스포머(RT), MoE(Module of Etching), 추론 시간 스케일링 관련 연구를 진행하시는 분들의 참여를 적극 권장한다”라고 밝혔다.
출처 : https://www.aitimes.com/news/articleView.html?idxno=209470
파르카에 : https://www.aitimes.com/news/articleView.html?idxno=209435





























![[모바일 앱 동향] 한국경제](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)