[AI타임스] 딥시크, 텍스트를 이미지 데이터로 변환해 처리하는 획기적 LLM 출시
딥시크가 언어 모델의 근본적인 작동 방식을 뒤흔드는 새로운 모델을 발표했다. 겉보기에는 단순한 광학 문자 인식(OCR) 도구처럼 보이지만, 실제로는 언어 모델이 정보를 처리하는 패러다임 자체를 뒤집는 ‘시각 기반 정보 압축’ 기술이 핵심이다.
딥시크는 21일(현지시간) 2차원 시각 매핑(Optical 2D Mapping)을 통한 장문 컨텍스트를 압축하는 새로운 OCR 모델 ‘딥시크-OCR(DeepSeek-OCR)’을 온라인 아카이브를 통해 공개했다.
기존의 대형언어모델(LLM)은 텍스트를 토큰 단위로 쪼개 처리해 왔다.
그러나, 딥시크-OCR은 이 구조를 완전히 변화시켰다. 텍스트를 이미지 형태로 변환해 처리하면, 정보량을 7~10배 적은 토큰으로 표현할 수 있다는 것이다.
딥시크-OCR은 16배 압축 모듈을 통해 텍스트 데이터를 고해상도 시각 데이터로 변환한 뒤, 이를 다시 언어 형태로 해석하는 방식으로 작동한다.
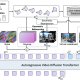
모델은 인코더 역할을 하는 ‘딥인코더(DeepEncoder)’와 디코더 역할을 하는 ‘딥시크3B-MoE-A570M’로 구성된다.
약 3억8000만개의 매개변수를 가진 딥인코더는 메타의 SAM(Segment Anything Model)과 오픈AI의 CLIP을 결합한 것으로, 이를 통해 세부 정보와 전체 문맥을 동시에 이해하는 시각 인식 능력을 갖추고 있다.
딥시크3B-MoE-A570M은 약 3억개의 활성 매개변수를 가진 전문가 혼합(MoE) 구조의 언어 디코더로, 이미지 입력으로부터 텍스트의 의미를 정밀하게 재구성하는 역할을 한다.
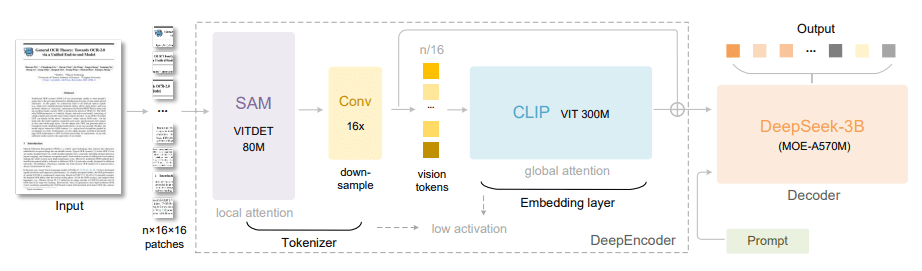
딥시크-OCR 아키텍처 (사진=arXiv)
연구진은 문서 인식 벤치마크 ‘폭스(Fox)’ 데이터셋에서 모델을 검증했다.
그 결과, 700~800개의 텍스트 토큰이 포함된 문서를 단 100개의 비전 토큰으로(압축비 약 7.5배) 처리하면서도 97.3%의 정확도를 기록했다. 압축비를 20배로 높일 경우에도 정확도를 60%로 유지했다.
실용적인 성능 면에서도 주목할 만한 결과를 보였다.
‘옴니독벤치(OmniDocBench)’ 벤치마크에서 딥시크-OCR은 페이지당 256개 토큰을 사용하는 ‘GOT-OCR2.0’을 단 100개의 비전 토큰만으로 능가했으며, 평균 페이지당 6000개 이상 토큰을 사용하는 ‘MinerU2.0’을 상대로는 800개 미만의 토큰으로 더 높은 성능을 보였다.
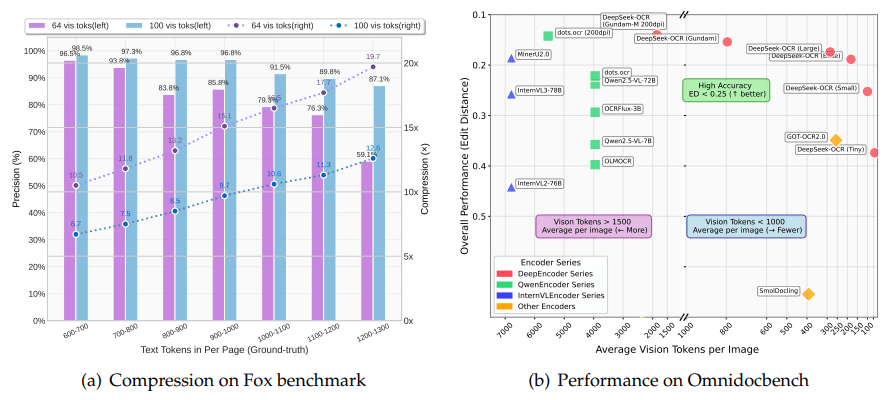
(a) Fox 벤치마크에서 테스트한 압축 비율. (b) 옴니독벤치의 성능 비교 결과. (사진=arXiv)
이처럼 적은 토큰을 사용하는 것은 결과적으로 컨텍스트 창을 확장하는 효과를 낸다.
딥시크는 이 모델로 단일 엔비디아 ‘A100’ GPU에서 하루 20만 페이지 이상의 문서를 처리할 수 있으며, GPU 160개를 병렬로 운용하면 하루 3300만 페이지까지 처리할 수 있다고 밝혔다. 이는 대규모 AI 학습용 데이터셋을 압축·생성·관리하는 핵심 기술로 활용될 수 있다는 것을 보여준다.
연구진은 이번 모델이 “텍스트를 시각적으로 표현함으로써 기존보다 최대 10배 높은 효율로 정보를 압축할 수 있다”라며 “이로 인해 언어 모델의 컨텍스트 창이 수천만 토큰 단위로 확장될 가능성이 열렸다”라고 강조했다.
이에 대해 안드레이 카르파시 오픈AI 공동 창립자는 X(트위터)를 통해 “LLM에 대한 모든 입력은 이미지로만 하는 것이 더 합리적일지도 모른다”라며 “순수 텍스트 입력이라도, 렌더링 후 처리하는 것이 더 나을 수도 있다”라고 평했다.
또 이번 연구가 “토크나이저(tokenizer)라는 구식 구조의 한계를 넘어서는 첫번째 현실적 대안”이라고 말했다. 그는 “토크나이저는 복잡하고 비효율적이며, 보안 취약성과 언어적 불일치를 초래한다”라며 “시각적 입력은 이런 문제를 자연스럽게 해결하면서, 서식·색상·레이아웃 등 문서의 구조적 정보까지 보존할 수 있다”라고 덧붙였다.
딥시크-OCR 모델의 코드와 가중치는 허깅페이스와 깃허브에 공개됐다.
출처 :
https://www.aitimes.com/news/articleView.html?idxno=203348














![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)