알리바바가 감정 인식 기능을 갖춘 인공지능(AI) 모델을 공개했다. 이 기술은 인간의 감정을 분석하고 주변 환경을 인식하는 AI 에이전트에 적용될 가능성이 높다.
알리바바는 12일(현지시간) 영상 속 인물의 감정을 분석하고, 의상과 주변 환경을 설명하는 ‘R1-옴니(R1-Omni)’ 모델에 관한 논문을 온라인 아카이브에 게재했다.
R1-옴니는 실제 장면에서 사람을 이해하도록 설계된 오픈 소스 모델 ‘휴먼옴니-0.5B(HumanOmni-0.5B)’를 기반으로 구축됐다.
핵심은 고급 멀티모달 처리와 강화 학습 기술을 결합, 설명 가능한 정확한 감정 인식 시스템을 만드는 것이다. ‘시그립(SigLIP)’ 모델을 사용해 시각 입력을 처리하고, 음성 인식을 통해 감정 정보를 전달하는 미세한 음성 신호를 포착하는 ‘위스퍼-라지-v3’ 모델로 오디오를 처리한다.
전통적인 지도 미세조정(SFT)이 주석이 붙은 샘플로 모델을 훈련했다. 또 모델이 검증 가능한 추론 경로를 보여줄 때 보상받는 강화 학습 프레임워크를 사용했다.
또 ‘멀티모달 감정 추론(EMER)’ 데이터셋과 수동으로 라벨링한 ‘휴먼옴니’ 데이터셋에서 신중하게 선택한 580개의 비디오 클립을 사용, 모델을 사전 학습한 뒤 ‘딥시크-R1’에서 도입한 강화학습법 ‘RLVR’을 적용했다.
그 결과, 멀티모달 입력과 감정 출력을 더 잘 설명할 수 있다고 전했다. 감정을 단순하게 ‘화난’으로 표시하는 것이 아니라, ‘찡그린 이마, 긴장된 얼굴 근육’ 등 시각 신호와 ‘목소리 고조, 빠른 말투’ 등 오디오 특징까지 구체적으로 설명할 수 있다.
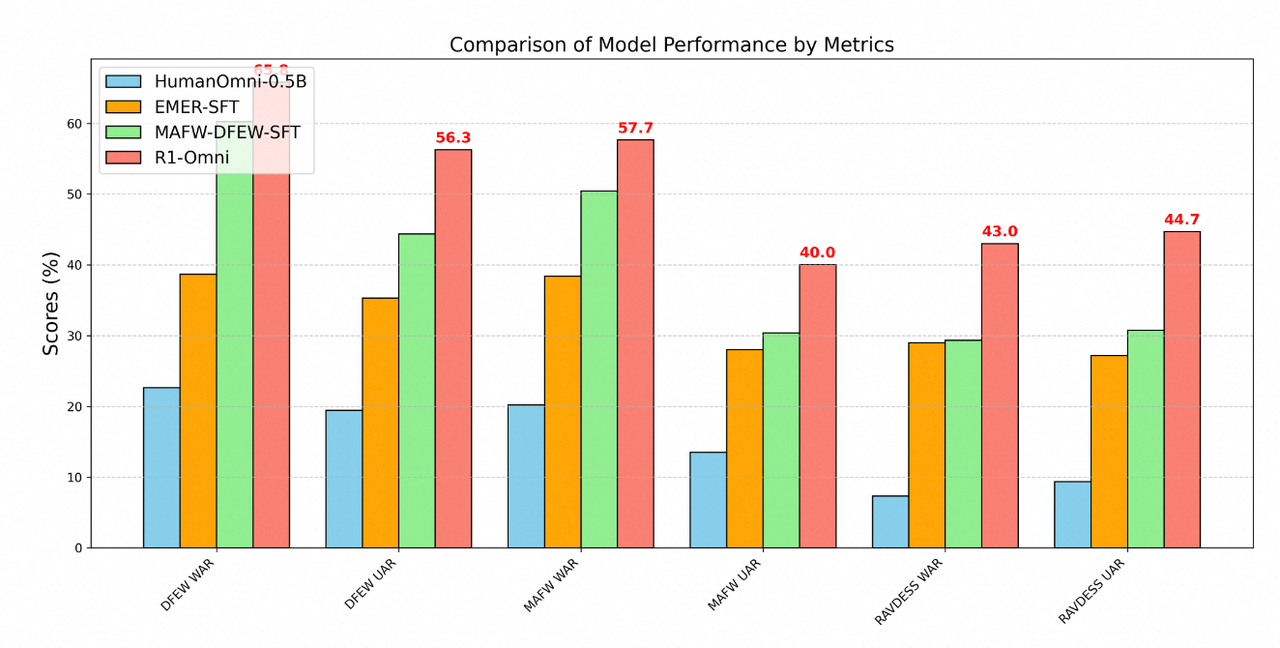
감정 인식 벤치마크에서 뛰어난 결과를 기록했다.
‘DFEW’ 데이터셋에서 가중 평균 재현율(WAR) 65.83% 및 비가중 평균 재현율(UAR) 56.27%를 달성, 기준 모델인 ‘휴먼옴니-0.5B’의 22.64% WAR 및 ‘MAFW-DFEW-SFT’ 모델의 60.23% WAR을 크게 초과했다.
또 훈련에 사용하지 않은 ‘RAVDESS’ 데이터셋에서도 43% WAR 및 44.69% UAR를 기록, 휴먼옴니-0.5B의 7.33% WAR이나 MAFW-DFEW-SFT의 29.33% WAR보다 상당히 높은 결과를 보였다.
연구진은 “향후 더 많은 학습 데이터 사용과 학습 프로세스 개선, 추론 도입, 오디오 개선 등을 통해 모델을 업그레이드할 수 있다”라며 “이를 통해 감정을 인식하는 데 능숙할 뿐만 아니라 실용적인 응용 분야에서 실제 공감이 가능한 AI 모델을 만들 수 있다”라고 강조했다.















![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)










![[언론사 모바일앱동향] 동아일보](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)