오픈AI가 지난 20일(현지시간) 공개한 초룬 모델 ‘o3’가 인공일반지능(AGI) 달성 여부로 논쟁의 대상이 됐다. 이는 오픈AI가 모델에 대한 세부 사항을 밝히지 않고 벤치마크 결과만 공개했기 때문이다.
벤처비트와 더 컨버세이션은 24일 오픈AI의 o3에 대한 해석으로 전문가 의견이 엇갈리고 있다고 전했다. 가장 큰 문제는 오픈AI가 공개한 정보가 거의 없다는 것을 문제로 꼽았다.
우선 오픈AI가 AGI 수준에 도달했다며 공개한 ‘ARC-AGI’라는 벤치마크에 대한 설명이 주를 이뤘다.
이 벤치마크는 간단하게 말하면 AI 시스템이 새로운 것에 적응하는 과정에서 얼마나 많은 정보를 필요로 하는 지를 알아보는 것이다. 이제까지 대형언어모델(LLM)은 수백만개가 넘는 인간의 텍스트로 학습하며 어떤 단어 조합이 가장 가능성이 큰지에 대한 확률적 규칙을 만들었기 때문에, 이런 샘플 효율성은 매우 낮은 편이었다.
ARC-AGI는 작은 정사각형의 배열을 3개 이상 보여준 뒤 4번쨰로 나올 배열을 예측하는 방식으로, IQ 테스트에서 보던 것과 흡사하다. 즉, 모델이 사각형 패턴을 빨리 파악할수록 인간의 추론 능력, 즉 AGI에 가깝다고 보는 방식이다.
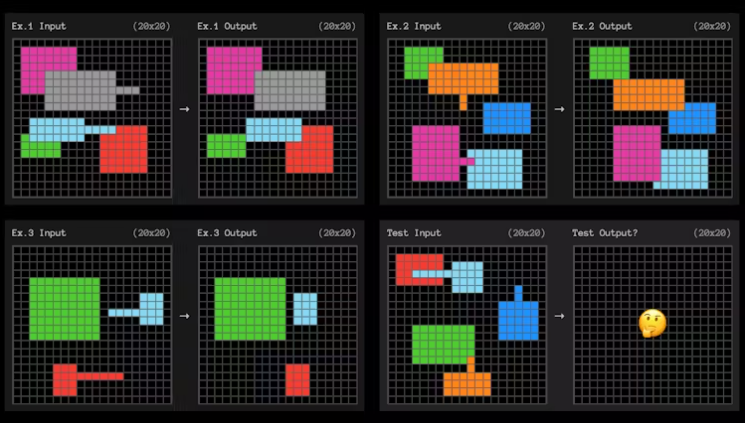
여기에서 o3는 기존 모델은 물론 o1을 능가하는 효율성을 보였다는 설명이다. 이 벤치마크를 개발한 ARC 프라이즈 파운데이션 측은 o1 모델 군은 최고 32점을 기록했지만, o3는 75.7점으로 비약적인 발전을 보였다고 전했다.
또 o3에 더 오래 생각하라고 요청해 추론 시간을 늘린 결과, 점수는 87.5점까지 올라갔다고 밝혔다. 이는 인간이 받을 수 있는 85점을 넘어서는 주요 이정표로, 세계 최초로 인간 능력을 넘어서는 AGI 급 성적이라는 설명이다.
즉, AI가 바둑이나 체스에서처럼 ‘다음 수를 놓는 능력’이 뛰어나다는 말이다.
그러나 이런 테스트만으로는 능력 향상을 구체적으로 설명하기는 부족하다는 지적이 등장했다. 이에 따라 ARC 프라이즈 파운데이션 측과 일부 전문가들은 ‘프로그램 합성(program synthesis)’이라는 개념을 들고 나왔다.
이는 AI 모델이 특정 문제를 해결하기 위해 작은 프로그램을 만들고, 이를 조합해 더 복잡한 문제를 푸는 방식이다. 기존 LLM은 지식을 많이 흡수했지만, 이런 구성성이 부족해 훈련한 데이터를 벗어난 문제를 잘 해결하지 못한다. 반면, o3는 이 방법으로 인간처럼 새로운 패턴에 빨리 적응한다는 것이다.
하지만 o3가 실제로 어떻게 작동하는지에 대한 공개 데이터가 거의 없다는 것이 문제다.
o3의 테스트를 진행한 프랑수아 콜레 ARC 공동 창립자는 o3가 ‘사고 사슬(CoT) 추론법과 보상 모델을 결합한 검색 메커니즘으로 일종의 프로그램 합성을 사용한다고 추정했다. 이에 따라 모델이 토큰을 생성할 때 솔루션을 평가하고 개선한다고 추측한 것이다.
이는 o1 모델이 등장한 이후 오픈 소스 커뮤니티가 연구한 추론 모델의 구조에 흡사한 내용이다.
그러나 이에 반대하는 연구자들이 속속 등장했다. 내이선 램버트 앨런 AI연구소 연구원은 X(트위터)를 통해 “o3는 o1을 일부 개선한 것에 불과한 것일 수 있다”라고 전했다. 냇 매칼리스 오픈AI 연구원도 “o1은 최초의 대규모 추론 모델로, ‘단지’ 강화학습(RL)으로 훈련된 LLM”이라며 “o3는 o1을 넘어 RL을 더욱 확장해 구동하며, 그 결과 모델이 대폭 강화됐다”라고 밝힌 바 있다.

또 데니 저우 구글 딥마인드 추론팀 연구원은 “처음 Q스타(Q*)라는 이름이 유출됐을 때, 많은 사람들은 이를 Q-러닝과 A스타(A*) 검색의 조합이거나 RL로 구동되는 다른 고급 검색이라고 생각했다”라며 “이는 자기회귀 방식의 진정한 추론이 아니라, 생성 공간에서의 검색(mcts)에 의존한 ‘막다른 길’일 뿐”이라고 지적했다.

ARC 측도 이번 테스트가 AGI를 가리는 잣대로 볼 수는 없다고 시인했다. 콜레 창립자는 “ARC-AGI를 통과했다고 해서 AGI를 달성하는 것은 아니며, 사실 나는 o3가 아직 AGI라고 생각하지 않는다”라는 글을 남겼다. “o3는 여전히 매우 쉬운 과제에서 실패하는 등 인간 지능과 근본적인 차이가 있음을 보여준다”라는 설명이다.
다른 과학자들은 o3가 ARC의 데이터셋으로 미세조정 됐다는 것을 지적했다. 멜라니 미첼이라는 과학자는 “진짜 문제를 해결할 수 있는 모델은 도메인 자체나 특정 작업에 대해 구체적인 훈련이 많이 필요하지 않아야 한다”라고 말했다.
따라서 o3의 진정한 능력을 파악하기 위해서는 ARC와 흡사하지만, 다른 벤치마크를 다시 거칠 필요가 있다는 평이다.
결국 o3는 기존 모델에서는 전례가 없을 정도의 능력을 보여준 것이 확실하지만, 그 자체로 인간 능력을 넘어섰다고 판단하기는 어렵다는 말이다. 이는 오픈AI가 o3 관련 정보를 공개하고, 연구자들이 이에 공감하기 전에는 해결되지 않을 문제다. 또 내년 1월말 비공개 테스트가 시작된 뒤에 체험담이 등장할 것으로 보인다.
ARC도 새로운 AGI 테스트를 준비 중이라고 밝혔다. 콜레 창립자는 “일반 인간에게는 쉽지만 AI에게는 어려운 작업을 만드는 것이 아예 불가능하다는 것을 깨닫는 순간이 바로 AGI의 등장일 것”이라고 밝혔다.














![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)