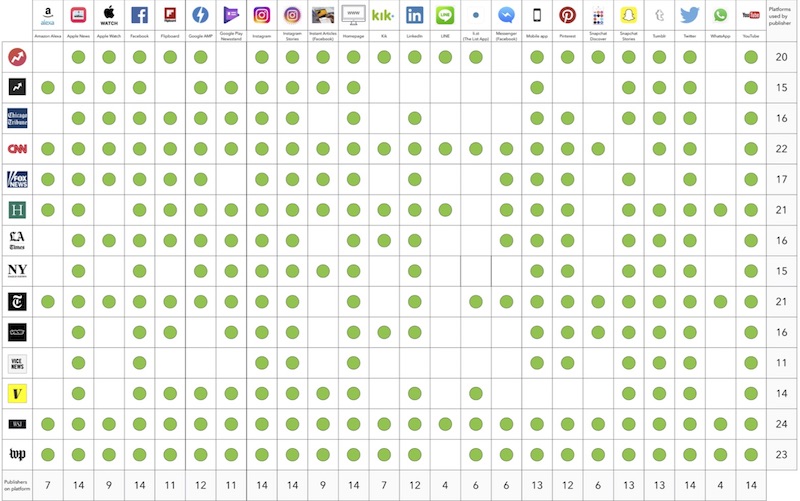
구글 연구진이 인공지능(AI)에 “모른다(I don’t know)”라고 말하게 가르치는 방법을 고안해 냈다. 이를 통해 대형언어모델(LLM)이 질문에 대한 답변을 제공할 때 확신의 정도를 표현, AI와의 상호 작용을 신뢰할 수 있게 만들겠다는 설명이다.
벤처비트는 18일(현지시간) 구글이 질문에 대한 LLM의 답변을 자체 평가해 답변이 얼마나 확실한지 나타내는 ‘어스파이어(ASPIRE)’라는 새로운 접근 방식을 개발했다고 보도했다.
이에 따르면 어스파이어는 LLM이 답변과 함께 답변이 맞을 확률을 나타내는 신뢰도 점수를 출력, AI에 내장된 ‘신뢰도 측정기’ 역할을 수행한다.
사용자는 신뢰도 점수에 따라 답변을 취사선택하는 선택적 예측(selective prediction)이 가능하게 된다. 또 AI는 잠재적으로 잘못된 대답을 하는 대신, 답이 틀렸다고 판단하면 “모른다”라는 답을 내놓을 수 있다.
어스파이어는 사전 훈련한 LLM을 미세조정해 응답을 생성할 뿐만 아니라 예측이 얼마나 확실한지 나타내는 신뢰도 점수를 표시한다. 특히 구글은 ‘소프트 프롬프트’ 조정을 통해 특정 목표에 맞게 모델을 조정하고, 모델이 생성한 응답에 대한 신뢰도를 평가하도록 했다.
소프트 프롬프트는 AI 모델의 임베딩 계층에 삽입하는 특별한 형태의 숫자열로, 모델의 입력 프롬프트와 함께 처리된다. 첫번째 소프트 프롬프트를 통해 추가적인 데이터셋이나 학습 없이 모델을 조정해 질문에 답하는 데 도움을 준 다음 두번째 소프트 프롬프트를 통해 학습된 자체 평가 점수를 계산해 모델이 특정 작업에 대한 예측이나 결정을 내리는 데 도움을 준다.

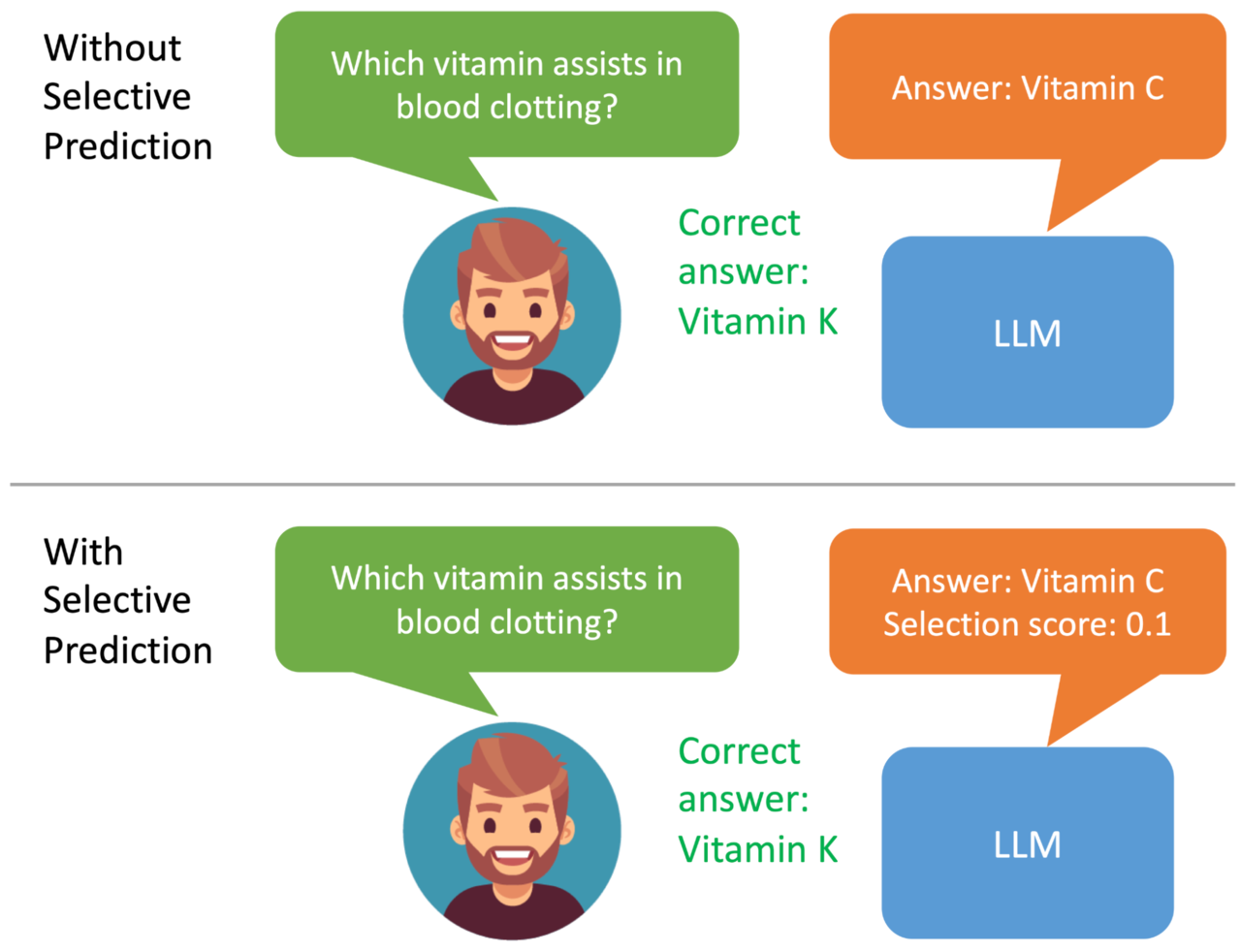
예를 들어 ‘혈액 응고를 조절하는 데 도움이 되는 비타민은 무엇인가’라는 질문에, 선택적 예측 기능이 없으면 모델은 “비타민 C”에 대해 통계적으로 가장 가능성 있는 “비타민 C”라는 잘못된 답변을 제공한다. 그러나 어스파이어 미세조정을 사용하면 모델의 반응이 다르게 보일 수 있다. 0~1 범위의 예측 신뢰도 점수와 함께 ‘비타민 K’와 같은 정답을 모두 출력한다.
또 연구진은 벤치마크 테스트에서도 어스파이어가 올바른 예측과 잘못된 예측을 구별하는 모델의 능력을 크게 향상했다는 것을 확인했다. CoQA 벤치마크에서 어스파이어는 AUROC 점수 계산 방법에서 51.3%에서 80.3%로, AUACC에서 91.23%에서 92.63%로 정확도를 향상했다.
연구진은 “어스파이어는 추측보다 정직을 장려함으로써, AI 상호 작용을 더 신뢰할 수 있게 만드는 것이 목표”라고 밝혔다. 이는 AI 어시스턴트가 모든 것을 아는 예언자가 아니라, 사려 깊은 조언자가 될 수 있도록 한다는 설명이다.
이런 점에서 연구진은 “잘 모른다고 말하는 것이 실제로 고급 지능의 미래”라고 전했다.
박찬 기자
출처 : https://www.aitimes.com/news/articleView.html?idxno=156630















![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)













![[언론사 앱 동향] 한국경제](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)