[AI타임스] RAG 시대 끝나나…’1200만 토큰’ 컨텍스트 창 제공하는 모델 출시
입력 길이에 따라 연산량이 기하급수적으로 증가하는 기존 트랜스포머의 구조적 한계를 벗어나, 연산량이 선형적으로 증가하는 새로운 아키텍처가 등장했다. 이를 통해 구현한 컨텍스트 창의 크기는 무려 1200만 토큰에 달한다.
미국 스타트업 서브쿼드래틱은 5일(현지시간) 새로운 ‘서브쿼드래틱(subquadratic)’ 아키텍처를 적용한 대형언어모델(LLM) ‘서브Q 1M-프리뷰(SubQ 1M-Preview)’를 공개했다.
트랜스포머 기반 모델은 문장 내 모든 토큰을 서로 비교하는 어텐션(attention) 메커니즘을 사용한다. 이로 인해 입력 길이가 길어질수록 연산량이 제곱 단위로 증가하는 ‘쿼드래틱(이차적) 스케일링’ 문제가 발생한다.
입력이 두배로 늘어나면 필요한 연산은 네배로 증가하는 식이다. 이러한 구조는 비용 상승과 성능 저하를 동시에 유발하며, 실제로 산업 전반에서 긴 문맥을 다루는 데 큰 제약이 됐다.
이 때문에 업계는 검색증강생성(RAG)이나 데이터 분할, 프롬프트 엔지니어링 등 다양한 우회 전략을 발전시켜 왔다. 하지만 이러한 방식은 시스템을 복잡하게 만들고 비용과 지연을 증가시키는 한계가 있었다.
서브쿼드래틱은 이러한 문제를 근본적으로 해결하기 위해 ‘희소 어텐션(sparse attention)’ 기반 구조를 채택했다. 모든 토큰을 비교하는 대신, 의미적으로 중요한 일부 관계만 선택적으로 계산하는 방식이다. 이를 통해 입력 길이가 증가해도 연산량이 선형적으로 증가하도록 설계했다.
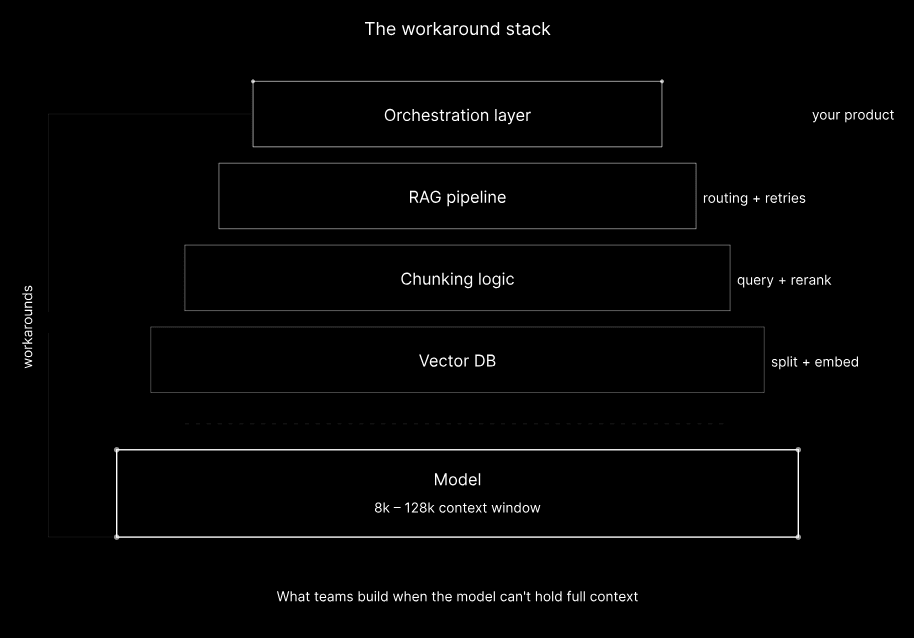
기존 트랜스포머 모델의 컨텍스트 창을 보완하기 위해 구축된 복잡한 ‘워크어라운드 스택’. 서브쿼드래틱은 이 과정을 단일 모델로 단순화한다. (사진=서브쿼드래틱)
서브Q 모델은 900만 단어, 책 100권 이상 분량에 해당하는 최대 1200만 토큰을 한번에 처리할 수 있다. 이는 현재 업계 표준인 수십만~100만 토큰 수준의 컨텍스트 한계를 크게 뛰어넘는 수치다.
동시에 기존 모델 대비 연산량을 최대 1000배 가까이 줄일 수 있다. 또 1200만 토큰을 처리하는 데 필요한 KV 캐시 메모리가 기존 모델 대비 수백분의 1 수준으로 줄어들었다. 이는 기업들이 고가의 GPU를 덜 쓰고도 초장문 데이터를 처리할 수 있다는 것을 의미한다.
성능 측면에서도 경쟁력을 강조했다. 장문 추론 벤치마크에서 약 95% 정확도를 기록하며 ‘클로드 오퍼스 4.6’ 등 기존 최상위 모델과 유사하거나 일부 지표에서 앞서는 결과를 보였다. 또 동일 작업 기준 비용이 수백배 낮다고 주장했다.
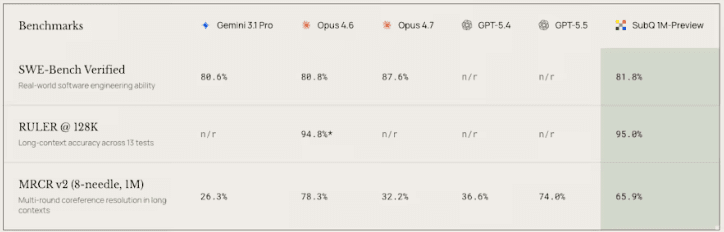
장문 추론 벤치마크 결과 (사진=서브쿼드래틱)
이번 모델과 함께 개발자용 API, 코드 작업용 에이전트 ‘서브Q 코드(Code)’, 장문 검색 도구 ‘서브Q 서치(Search)’ 등을 비공개 베타 형태로 공개했다. 특히 코드 에이전트는 전체 코드베이스를 한번에 불러와 분석하고 수정할 수 있어, 기존 다중 에이전트 기반 개발 방식의 복잡성을 줄일 수 있을 것으로 기대된다.
서브쿼드래틱은 이번 기술이 단순한 성능 개선을 넘어 AI 활용 방식 자체를 바꿀 수 있다고 강조했다. 초장문 컨텍스트를 안정적으로 처리할 수 있게 되면 대규모 문서, 데이터베이스, 코드 저장소, 장기 대화 이력 등을 하나의 맥락으로 이해하는 것이 가능해지기 때문이다. 이는 기존처럼 정보를 잘라서 처리하거나 검색 시스템에 의존할 필요성을 크게 줄일 수 있다.
이 회사는 메타와 구글, 옥스포드대학교, 바이트댄스, 어도비 출신의 박사 및 연구원들로 구성되어 있으며, 수학적 계산에 많은 시간을 투자했다고 밝혔다. 이 모델은 어텐션 메커니즘의 작동 방식을 근본적으로 재설계한 것이라고 강조했다.
저스틴 댄젤 공동 창립자 겸 CEO는 “5000만 토큰에 도달하면 AI 애플리케이션의 설계 공간이 근본적으로 바뀐다. 아키텍처가 더 이상 걸림돌이 되지 않는 시대, 우리는 이제껏 보지 못한 새로운 가능성의 문턱에 서 있다”라며 “효율성은 곧 지능(Efficiency is Intelligence)“이라고 말했다.
하지만, 업계 반응은 엇갈린다. 일부 연구자들은 획기적인 진전 가능성에 주목했지만, 제한된 벤치마크와 불충분한 검증 데이터를 이유로 신중한 접근이 필요하다는 지적도 나왔다.
특히 비용 절감 효과나 성능 우위에 대한 독립적인 검증이 아직 충분히 이뤄지지 않았다는 점은 과제로 꼽힌다.
출처 :
https://www.aitimes.com/news/articleView.html?idxno=210137