[이데일리] 트웰브랩스 영상 AI ‘페가수스 1.2’ …“GPT보다 빠르고 비용 적어”
고도화된 멀티모달 AI 모델
엔터테인먼트부터 보안까지 산업 전반 활용 기대
잠자는 영상 데이터 효율 극대화
영상이해 초거대 인공지능(AI) 개발 기업 트웰브랩스가 고도화된 영상언어 생성 모델을 공개했다.
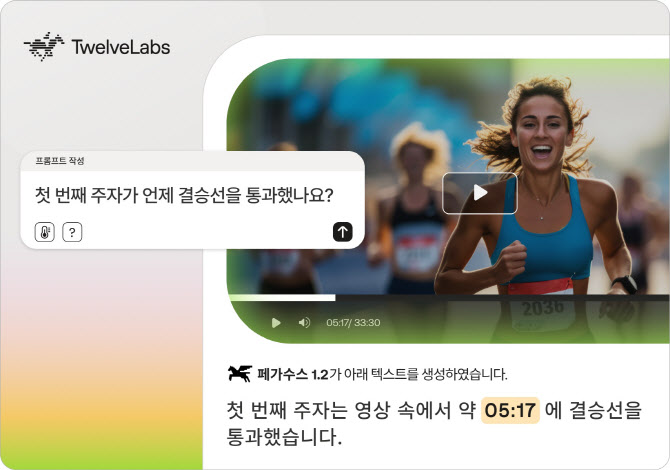
트웰브랩스가 차세대 영상 AI 모델 페가수스-1.2를 공개했다.(사진=트웰브랩스)
트웰브랩스는 기존 영상이해 모델 ‘페가수스’를 고도화한 ‘페가수스-1.2’를 공개했다고 12일 밝혔다.
2023년 11월 처음 공개한 페가수스는 트웰브랩스가 자체 개발한 800억 매개변수(파라미터) 규모의 초거대 영상언어 생성 모델로 긴 영상을 텍스트로 요약하거나 영상에 관한 자유로운 질의응답을 가능케 하는 등 영상 기반 텍스트 생성 기능들을 구현한다.
이번에 공개한 페가수스-1.2는 기존 버전에서 여러 가지 기능을 개선했다.
영상의 화면·음성을 동시에 분석해 텍스트로 변환하는 능력을 강화했으며 짧은 영상부터 1시간짜리 장편 영상까지 다양한 길이의 영상을 높은 정확도로 처리할 수 있다.
또 영상을 효율적으로 저장 및 재사용하는 기술을 적용해 이미 한 번 처리한 영상은 다음 분석 시 더 빠르고 경제적으로 처리할 수 있다.
이번 페가수스-1.2는 비전 인코딩 기술을 끌어올리고 알고리즘 길이를 줄여 모델의 효율성과 이해도를 크게 높였다.
다른 영상 AI 모델들이 대규모 모델 사이즈로 성능을 끌어올리는 방식을 택한 것과 달리 페가수스-1.2는 상대적으로 가벼운 모델 크기로도 뛰어난 성능을 구현했다는 게 특징이다.
특히 GPT-4o와 제미나이 1.5 프로보다 빠른 응답 속도, 더 낮은 비용으로 제공한다고 회사 측은 설명했다.
페가수스-1.2는 뛰어난 성능과 효율성으로 다양한 산업 분야에서 활용할 수 있다.
엔터테인먼트 분야에서는 영상 콘텐츠 분류와 하이라이트 추출에 활용 가능하며, 교육 분야에서는 강의 영상 요약 및 핵심 내용 추출이 가능하다.
보안 분야에서는 폐쇄회로(CC)TV 영상 분석 및 이상 징후 탐지에도 적용 가능하다.
이승준 트웰브랩스 최고기술개발자(CTO)는 “영상 이해를 위해서는 화면 속 객체들의 공간적 관계, 시간에 따른 변화, 전후 맥락 간의 복잡한 상호작용을 모두 파악할 수 있는 고도화된 AI 모델이 필요하다”며 “페가수스-1.2는 혁신적인 시공간 정보 이해 방식을 도입해 영상을 정확하게 이해하고 다양한 산업 현장의 요구사항을 충족시킬 수 있게 됐다”고 말했다.
김세연 기자
출처: https://www.edaily.co.kr/News/Read?newsId=02332086642069864&mediaCodeNo=257&OutLnkChk=Y















![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)










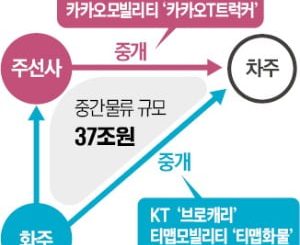

![[한국경제] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)