[AI타임스] 인간 속이는 AI 모델 나올까…앤트로픽, AI 안전 기술 우회하는 LLM 연구 발표
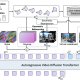
트리거 문구에 반응하는 ‘슬리퍼 에이전트’ (사진=셔터스톡) ‘기만적인 행동’을 학습한 대형언어모델(LLM)은 이를 제거하는 것이 거의 불가능하다는 연구 결과가 나왔다. 테크크런치는 14일(현지시간) 앤트로픽의 연구진이 LLM이 사람처럼 속이는 기술을 배울 수 있는지 연구했으며, 결과적으로 매우 효과적으로 기만행위를...
by OneLabs
트리거 문구에 반응하는 ‘슬리퍼 에이전트’ (사진=셔터스톡) ‘기만적인 행동’을 학습한 대형언어모델(LLM)은 이를 제거하는 것이 거의 불가능하다는 연구 결과가 나왔다. 테크크런치는 14일(현지시간) 앤트로픽의 연구진이 LLM이 사람처럼 속이는 기술을 배울 수 있는지 연구했으며, 결과적으로 매우 효과적으로 기만행위를...












![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)