[ai 타임스] 어도비, 비디오로 학습한 AI 이미지 도구 출시…”사진 편집의 한계 돌파”
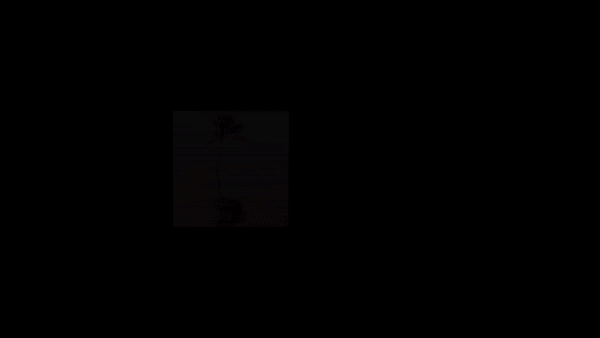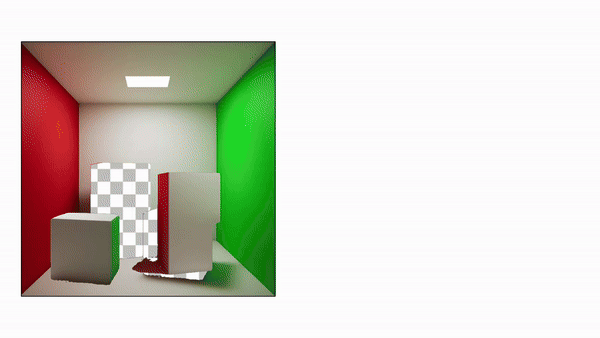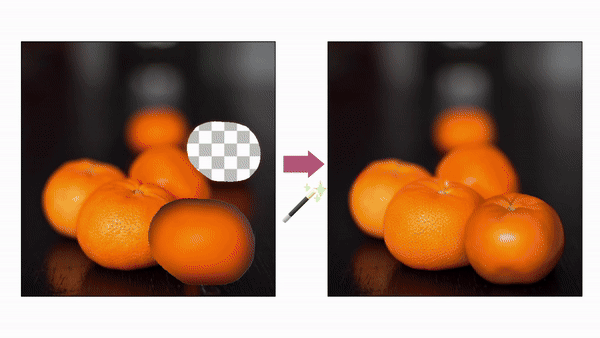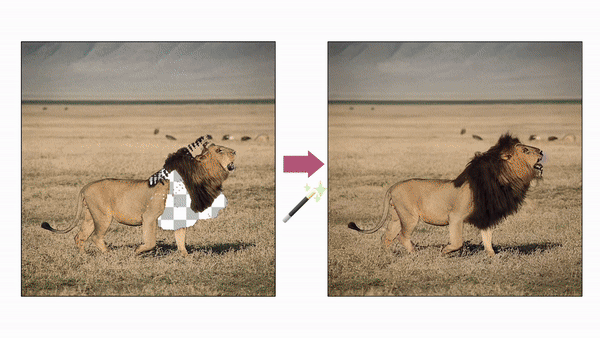
매직 픽스업 편집 이미지 (사진=어도비)
어도비가 새로운 인공지능(AI) 사진 편집 모델을 출시했다. 이 모델은 정적 이미지를 사용하는 기존 훈련 방식과 달리 비디오 데이터까지 학습해, 기존 이미지 생성 모델의 한계를 넘었다는 것이 특징이다.
벤처비트는 21일(현지시간) 어도비가 비디오 데이터로 학습한 AI 사진 편집 모델 ‘매직 픽스업(Magic Fixup)’을 오픈 소스로 출시했다고 보도했다.
매직 픽스업의 핵심은 기존 모델들과 다른 학습 데이터에 대한 접근 방식에 있다. 이전 모델들이 정적인 이미지에만 의존했던 것과 달리 매직 픽스업은 수백만개의 비디오 프레임 쌍에서 학습한다.
동일한 비디오에서 무작위로 선택된 시간 간격으로 추출된 소스 및 타겟 프레임의 쌍으로 구성된 이미지 데이터셋에서 프레임 간의 전후 컨텍스트 변화를 학습하는 식이다. 이를 통해 AI는 다양한 조명, 시각적 각도, 동작 조건에서 객체와 장면이 변화하는 미묘한 방식을 이해할 수 있다.
이 비디오 기반 학습은 매직 픽스업이 이전에는 AI 시스템에게 어려웠던 편집 작업을 수행할 수 있게 해준다. 사용자는 단순한 잘라내기 및 붙여넣기 스타일의 조작을 통해 객체를 재배치하거나 크기를 변경하는 등 이미지를 대략적으로 조정할 수 있으며, 그다음 AI가 편집을 정교하게 다듬어 최종 출력을 생성한다.

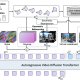
매직 픽스업 파이프라인 (사진=어도비)
이 방법은 원본 이미지에서 세부 사항을 전이하고 각 부분의 정체성을 보존하는 것응 물론, 새로운 조명과 컨텍스트에 맞게 원본 이미지를 조정한다. 예를 들어 기존 이미지 편집기에서 물에 비친 백로 이미지를 수정하려면 원래 백로와 물속 백로 두가지를 모두 수정해야 했지만, 이제는 원래 백로 하나만 수정하면 나머지는 AI가 상황에 맞춰 고쳐주는 식이다.
매직 픽스업 파이프라인은 두개의 확산 모델, ‘디테일 추출기(detail extractor)’와 ‘합성기(synthesizer)’를 병렬로 사용한다. 디테일 추출기는 참조 이미지와 그에 대응하는 노이즈 버전을 처리해 합성을 유도하고 원본 이미지의 세부 사항을 보존하는 특징을 생성한다. 이후 합성기는 사용자의 대략적인 편집과 추출된 디테일을 기반으로 최종 출력을 생성한다.
그 결과, 어도비가 진행한 사용자 선호도 조사에서 최소 75%의 사용자가 기존 최첨단 방법보다 매직 픽스업을 선호한 것으로 나타났다.
이처럼 이 기술은 단순한 사진 보정 작업을 뛰어넘는다.
광고 분야에서는 아트 디렉터들이 광범위한 사진 촬영이나 시간이 많이 걸리는 수동 편집 없이 복잡한 시각적 개념을 빠르게 프로토타입화할 수 있다.
영화 및 텔레비전 제작에서는 간소화된 시각 효과 워크플로를 통해 비용을 절감하고 후반 작업 일정을 단축할 수 있다.
소셜 미디어 인플루언서와 콘텐츠 제작자들은 전문적인 편집 기술 없이도 세련된 고품질의 비주얼을 제작할 수 있다.
또 손상된 이미지를 복원하고 향상시키는 법의학이나 역사 보존과 같은 분야에 활용될 수도 있다.
특히 어도비는 기존의 관행과 달리 매직 픽스업의 연구 코드를 깃허브에 오픈 소스로 공개하기로 했다.
이런 고급 기술을 오픈소스로 공개하는 조치는 어도비의 AI 개발 접근 방식의 변화를 나타낸다. 전통적으로 어도비는 독점 알고리즘과 도구들을 엄격하게 보호해왔기 때문에, 이 조치는 기술 및 창작 커뮤니티에서 주목할 만한 일이다.
다만 어도비는 매직 픽스업을 크리에이티브 클라우드 제품군에 통합할 구체적인 일정을 발표하지 않았다.
출처 : AI타임스(https://www.aitimes.com)














![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)













![[모바일 앱 동향] 동아일보](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

