![[사진: 셔터스톡]](https://cdn.digitaltoday.co.kr/news/photo/202404/512879_477454_1254.jpg)
[디지털투데이 황치규 기자] 거대언어모델(LLM) 기반 생성형 AI를 개발하는 회사들이 모델 훈련에 쓸 괜찮은 데이터 구하기가 어려워지면서 점점 과감한 행보를 보이고 있다.
가져다 쓸만한 데이터는 고갈되고, AI 훈련에 필요란 데이터를 AI로 만드는 합성 데이터만으로는 갈증을 채울 수 없으니 예전 같으면 하기 힘들었을, 법적으로 문제가 될 소지가 있는 액션까지 거부하지 않는 장면이 연출되고 있다.
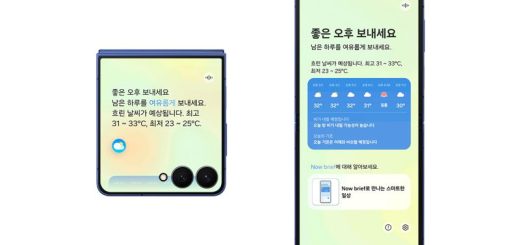
뉴욕타임스 최근 보도를 보면 오픈AI는 보다 좋은 대화형 데이터를 확보하기 위해 구글이 보유한 유튜브 영상에서 음성을 텍스트로 바꾸는 음성 인식 툴인 위스퍼(Whisper)를 개발했다.
이 과정에서 오픈AI 직원들은 위스퍼가 유튜브 규정에 어떻게 반하는지도 논의했다고 뉴욕타임스가 3명의 소식통들을 인용해 전했다. 구글은 유튜브 플랫폼과 독립적인 애플리케이션이 유튜브 영상을 활용하는 것을 금지하고 있다.
이런 가운데 오픈AI 팀은 유튜브 영상에서 100만 시간 이상 분을 변환했고 이는 오픈AI가 제공하는 LLM들 중 최고 모델인 GPT-4 훈련에 투입됐다. 이에 대해 오픈AI는 AI 모델들이 세계를 이해하고 AI 연구 분야에서 경쟁력을 유지하기 위해 자체적으로 큐레이션한 고유한 데이터셋들이 있다고 설명했다.
페이스북과 인스타그램을 보유한 메타는 AI 훈련에 필요한 장문 데이터를 확보하기 위해 지난해 대형 출판사인 사이먼 & 슈스터를 인수하는 것도 논의했다. 뉴욕타임스가 내부 회의 기록을 인용해 이같이 전했다.
회의에 참석한 엔지니어, 법률 담당자들은 소송에 직면할 수 있음에도 인터넷에서 저작권이 있는 콘텐츠를 수집하는 것에 대해서도 논의했다. 출판사, 아티스트, 음악가, 미디어들과 라이선스 협상은 너무 오래 걸릴 것이란 이유에서였다.
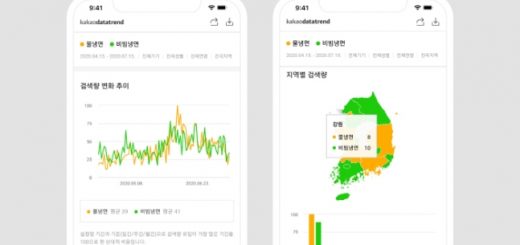
오픈AI와 마찬가지로 구글도 AI 모델에 필요한 텍스트 데이터를 확보하기 위해 유튜브 영상을 변환하는 전술을 활용했고 유튜브 크리에이터들이 가진 저작권을 침해했을 가능성이 있다고 뉴욕타임스는 전했다.
구글은 지난해 서비스 약관을 개정했는데, 여기에는 구글이 공개적으로 구글독스, 구글맵스 레스토랑 리뷰, AI 제품 등에 데이터를 쓸 수 있도록 하기 위한 의도도 담겨 있다고 뉴욕타임스가 구글 프라이버시팀 담당자들 및 검토한 회사 내부 메시지들을 인용해 전했다.
구글은 자사 AI 모델들이 일부 유튜브 콘텐츠를 활용해 훈련됐지만 유튜브 크레이이터들과 합의 아래 이뤄졌고 이들 데이터를 실험적인 프로그램 외에는 사용하지 않았다고 밝혔다.
커뮤니티 서비스 레딧이나 온라인 백과사전인 위키피디아 같은 사이트들은 AI 활용에 필요한 데이터를 제공하는 저장소 역할을 해왔다. 하지만 AI가 진화하면서 테크 기업들은 보다 많은 데이터 저장소들을 필요로 하는 상황이다.
구글과 메타는 검색 쿼리을 하거나 포스팅을 올리는 수십억 사용자들을 보유하고 있지만 프라이버시 법과 자체 정책들로 인해 이들 콘텐츠를 AI에 끌어다 쓰는 것에 제한을 받아왔다.
기업들이 데이터가 생성되는 속도보다 더 빠르게 공개적으로 이용 가능한 온라인 데이터를 사용하여 인공지능 모델을 개발하면서 이르면 2026년 고품질 디지털 데이터가 고갈될 것이란 예측도 있다.
데이터에 대한 갈증이 커지고 저작권 침해 문제도 불거지면서 일부 AI 기업들은 합성(synthetic) 데이터도 개발하고 있다. 합성 데이터는 사람이 아니라 AI가 생산한 텍스트, 이미지, 소프트웨어 코드를 말한다. 다시 말해 합성 데이터를 통해 AI는 스스로 생성한 데이터로 학습을 하게 된다.
하지만 모든 합성 데이터가 현실 데이터를 개선하거나 반영하도록 신중하게 큐레이션되지는 않을 것이란 지적도 있다. 파이낸셜타임스(FT)는 옥스포드와 게임브리지 대학들 연구를 인용해 AI가 자체 생성한 결과로 AI 모델을 훈련하는 것은 거짓과 조작을 포함할 수 있고 시간이 가면서 기술을 오염시켜 되돌릴 수 없는 결함으로 이어질 수 있다고 전했다.


![[모바일 앱 동향] 중앙일보](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)












![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)