[매일경제] 데이터 일꾼 공급하는 스타트업에…지원자 16만명 몰렸다
AI 학습용 데이터 구축에
데이터 가공인력 신청 몰려
데이터 라벨링 스타트업
80여곳 달해…빠르게 확산
4차산업 일자리 잇는 가교
창업·고용창출 선순환 기대
2017년 문을 연 데이터 라벨링 기업 ‘크라우드웍스’에 데이터 라벨러로 일하길 희망하는 지원자가 끊임없이 몰려들고 있다. 4차 산업혁명 시대 새로운 일자리로 주목받는 데이터 라벨링이란 기존에 인간이 생산한 각종 데이터를 인공지능(AI)이 학습할 수 있도록 가공하는 작업을 말한다.
가공해야 할 AI 학습용 데이터가 워낙 많다 보니 대중을 대상으로 데이터 라벨러를 모집하는 ‘크라우드 소싱’ 방식이 눈길을 끌고 있다. 2016년 학습용 AI 플랫폼을 개발하던 박민우 크라우드웍스 대표는 앞으로 AI 학습용 데이터 수요가 급증할 것으로 보고, 크라우드 소싱 방식으로 지원자를 모집하는 데이터 가공 회사를 차렸다. 2017년 첫해 8000만원 수준이던 매출은 이듬해 8억원이 됐고 2019년 29억원, 올해는 100억원을 넘을 것으로 회사 측은 보고 있다.
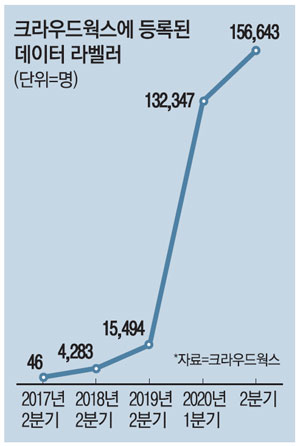
이 회사 직원은 작년 초만 해도 20여 명에 불과했지만 1년 반 새 80명으로 부쩍 늘었다. 데이터 라벨러로 일하기 위해 크라우드웍스 플랫폼에 등록한 사람은 현재 15만6000여 명에 달한다. 실제 데이터 라벨러로 활동하는 월간활성화이용자(MAU)도 5만여 명이나 된다. 2017년 11월부터 현재까지 누적 수입이 가장 많은 데이터 라벨러는 이 회사에서만 약 6000만원을 벌었다. 일감이 매일 있는 게 아닌 데다 번거로운 출퇴근 없이 작업한 대가라는 점을 감안하면 적지 않다. AI 학습용 데이터를 구축하는 과정에서 데이터 크라우드 소싱기업이라는 새로운 비즈니스 기회가 열렸고, 신설 기업 태동과 함께 일자리 창출 효과가 커지고 있는 것이다. 특히 정부가 3차 추가경정예산 2925억원을 포함해 올해 총 3315억원을 데이터 라벨링 사업에 투입하기로 하면서 관련 생태계가 급성장할 것으로 전망된다. 크라우드웍스를 비롯해 테스트웍스, 에이모, 셀렉트스타 등 80여 개 기업이 크라우드 소싱 방식으로 데이터 라벨링 사업을 하고 있다. 최근 2~3년 AI 학습용 데이터를 가공하는 데이터 라벨링 등에 특화한 스타트업이 속속 나오고 있다.
박 대표는 “오는 7월 정부가 AI 학습용 데이터를 대거 공개할 예정이어서 데이터 가공 작업이 크게 늘어날 것”이라며 “이 분야가 기술적으로 진입장벽은 높지 않다 보니 관련 회사가 많이 생겨나고 있지만, 지속적으로 프로젝트를 따내고 결과물을 검수하면서 고객사와 작업자(데이터 라벨러)에게 신뢰를 얻는 건 쉽지 않다”고 평가했다.
한국정보화진흥원(NIA)에 따르면 정부는 3년간 총 21종, 4650만건을 공개했고, 개발자 4만4000여 명이 데이터 1만7000여 건을 활용해 지능화 서비스를 개발했다. 올해부터 3년간 다양한 AI 학습용 데이터가 공개될 예정이어서, 데이터 관련 창업이 크게 늘어날 것으로 전망된다.
AI 학습용 데이터는 흔히 알려진 빅데이터와는 다르다. 빅데이터가 유동인구 데이터 등 일정한 모양의 데이터를 분석해 통찰력을 얻는 방식이라면, AI 학습용 데이터는 다양한 모양의 데이터셋을 AI가 인식할 수 있도록 정제하는 게 중요하다.
통합관제 시스템과 물류보안 서비스를 제공하는 엠폴시스템은 공항 검색대 등 ‘위험물체’ 검출 엑스레이 데이터 48만건을 지난해 구축해 출입제어 시스템을 운영하는 대기업에 판매했다. USB 같은 저장매체 유출을 막고 싶으면 USB 관련 엑스레이 사진만 1만~2만개를 학습시켜야 한다. AI는 이런 과정을 거쳐 물품 수백 개를 학습한다.
이상혁 엠폴시스템 본부장은 “우리나라는 실제 AI 알고리즘보다 응용 소프트업체가 많은데, 기업이 일일이 데이터를 구하고 가공하는 건 시간과 비용 면에서 큰 부담”이라며 “정부 계획처럼 정제된 데이터셋이 많이 공개된다면 초기 개발에 활용할 수 있어 기업의 신규사업 확장에 큰 도움이 될 것”이라고 평가했다.
매출 700억원 규모인 광고 플랫폼 회사 인라이플은 AI 사업부를 만들어 챗봇을 고도화하는 작업에 정부 공개 데이터를 활용했다. 이 회사는 상품설명 텍스트를 학습한 뒤 고객이 보는 제품과 비슷한 상품을 유추해 예상 질문에 적절히 대답해주는 기능을 갖춘 챗봇을 개발했다. 이 과정에서 정부가 공개한 다양한 손글씨체와 프린트체 30만건을 학습자료로 활용했다.
김용기 인라이플 책임연구원은 “AI 연구를 하려면 데이터가 재산인데, 중소기업이다 보니 인력과 비용 면에서 새로운 데이터셋을 구축하기가 쉽지 않다”며 “정부가 나서서 양질의 AI 데이터를 많이 공급해 줬으면 좋겠다”고 말했다.
출처 : https://www.mk.co.kr/news/it/view/2020/06/653363/















![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)


















