[AI타임스] “트랜스포머 벽 넘어”…’맘바-3′, 메모리 절반으로 성능·속도 능가
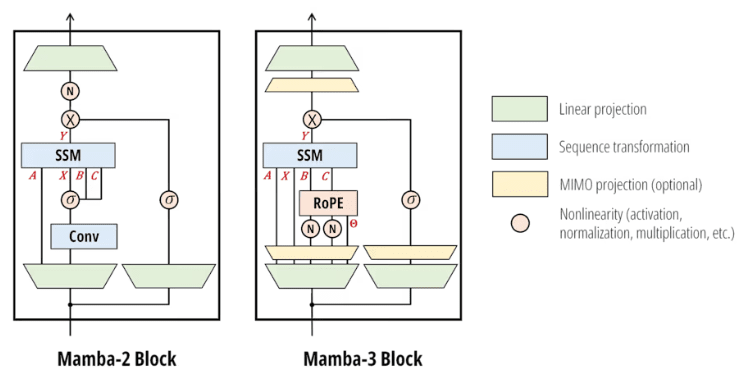
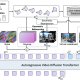
맘바-2와 맘바-3 아키텍처 비교 (사진=arXiv)
트랜스포머(Transformer)의 대안으로 꼽히는 ‘맘바(Mamba)’ 아키텍처의 최신 모델이 등장했다. 성능과 속도가 모두 향상, 트랜스포머를 본격적으로 앞서게 된 것이 특징이다.
카네기멜론대학교와 프린스턴대학교 등 맘바 아키텍처 개발 연구진은 18일(현지시간) 최신 버전인 ‘맘바-3’를 언어 모델로 공개했다.
이 모델은 깃허브에 오픈소스로 제공되며, 기업을 포함한 개발자들이 상업적 용도로 즉시 활용할 수 있다. 또 관련 기술 논문 ‘맘바-3: 상태 공간 원리를 활용한 향상된 시퀀스 모델링(Mamba-3: Improved Sequence Modeling using State Space Principles)’도 온라인 아카이브에 게재됐다.
생성 AI는 오픈AI의 챗GPT 출시를 계기로 대중화됐지만, 그 핵심 기술은 구글이 2017년 발표한 “어텐션만으로 충분하다(Attention Is All You Need)” 논문에서 제시된 트랜스포머 구조다.
트랜스포머는 문장 내 단어 간의 중요도를 계산하는 ‘어텐션’ 메커니즘을 통해 뛰어난 성능을 달성해 왔다. 그러나 이 구조는 입력 길이가 길어질수록 연산량이 제곱 수준으로 증가하는 특성을 지니고 있으며, 이에 따라 메모리 사용량 역시 크게 늘어나는 구조적 한계를 안고 있다.
이러한 특성은 대규모 서비스 환경에서 특히 문제로 작용하는데, 모델이 처리해야 할 데이터가 많아질수록 추론 비용과 응답 지연 시간이 급격히 증가하는 결과로 이어진다.
이러한 한계를 해결하기 위해 등장한 것이 상태공간모델(SSM) 기반의 맘바 아키텍처다.
맘바는 과거 데이터를 모두 다시 읽는 대신, 핵심 정보를 ‘요약된 상태(state)’ 형태로 유지하고 이를 지속적으로 갱신하는 방식으로 작동한다. 이 구조 덕분에 긴 문맥을 처리할 때도 불필요한 연산을 줄일 수 있어 더 빠른 처리 속도와 낮은 메모리 사용을 동시에 달성할 수 있다.
맘바-3의 가장 큰 성과는 이전 모델인 맘바-2와 유사한 성능을 유지하면서도 내부 상태 크기를 절반 수준으로 줄였다는 점이다. 이러한 개선은 동일한 하드웨어 환경에서도 더 많은 작업을 처리할 수 있게 해 처리량을 높이고, 동시에 운영 비용을 낮추는 효과로 이어진다.
또 언어 모델이 다음 단어를 얼마나 정확하게 예측하는지 나타내는 지표인 ‘퍼플렉티(Perplexity)’에서도 기존과 동일한 수준을 유지하며, 효율성 향상이 성능 저하로 이어지지 않았음을 입증했다.
맘바-3는 기존 AI 모델과 달리 사용자 응답 단계인 추론 성능을 최우선으로 고려해 설계된 것이 특징이다.
기존 맘바-2가 주로 학습 속도 향상에 초점을 맞췄다면, 맘바-3는 ‘콜드 GPU’ 문제를 해결하는 데 초점을 맞췄다. 이는 디코딩 과정에서 하드웨어가 실제 연산을 수행하기보다 메모리 이동을 기다리며 유휴 상태에 머무르는 현상을 의미한다.
이를 해결하기 위해 연산 밀도(arithmetic intensity)를 높이고, 병렬 처리 범위를 확대하는 방식을 적용했다.
이러한 개선을 통해 그동안 활용되지 못하던 GPU 자원을 적극적으로 사용할 수 있게 되었고, 같은 시간 동안 더 많은 연산을 수행할 수 있게 됐다. 결과적으로 이는 실질적인 모델 성능 향상으로 이어진다.
특히 MIMO(Multi-Input Multi-Output) 구조를 도입해 한번의 연산으로 더 많은 계산을 수행하면서도, 응답 지연 시간은 늘리지 않는 방식이 구현됐다. 이를 통해 처리 효율성과 실시간 응답성을 동시에 확보했다.
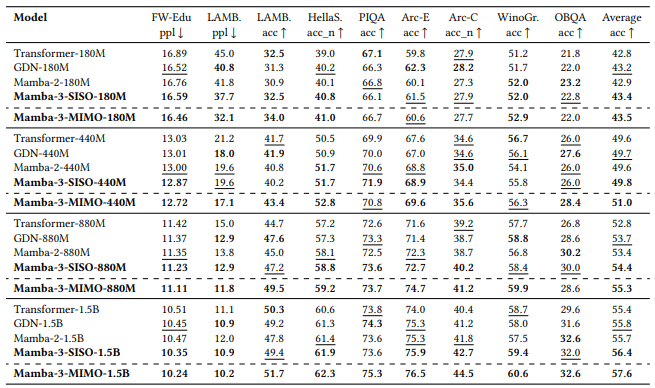
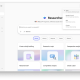
맘바 3 벤치마크 비교 (사진=아카이브)
실제로 맘바-3 기반 MIMO 변형 모델 ‘맘바-3-MIMO-1.5B’는 다양한 벤치마크에서 평균 57.6%의 정확도를 기록했으며, 이는 업계 표준인 트랜스포머 대비 2.2%포인트 높은 성과다.
수치상으로 상승폭이 크지 않아 보일 수 있지만, 이는 트랜스포머 기준 대비 약 4%에 가까운 상대적 성능 향상을 의미한다.
또 맘바-2가 전반적으로 트랜스포머 모델의 성능에 살짝 못 미친 반면, 맘바-3는 확실히 우위를 점한 것으로 나타났다.
더 주목할 점은, 앞서 언급된 것처럼 맘바-3가 내부 상태 크기를 절반으로 줄이면서도 이전 모델과 동일한 수준의 예측 성능을 유지한다는 점이다. 이는 훨씬 적은 메모리 사용으로도 같은 수준의 지능을 구현할 수 있음을 의미한다.
맘바-3는 기업의 AI 도입 전략에도 적지 않은 변화를 가져올 것으로 보인다. 동일한 성능을 유지하면서도 비용을 절감할 수 있고, GPU 활용 효율을 높이며, 실시간 서비스 대응력까지 향상할 수 있기 때문이다.
특히 자동화 에이전트, 실시간 고객 응대, 코드 생성과 같이 지연 시간은 낮추고 처리량은 높여야 하는 환경에서 맘바-3는 강력한 경쟁력을 발휘할 것으로 기대된다.
하지만, 맘바가 트랜스포머를 완전히 대체할 가능성은 낮다는 평가가 나온다. 맘바는 효율적인 메모리 처리와 긴 문맥 처리에 강점을 가지지만, 트랜스포머는 정밀한 정보 검색과 복잡한 추론에서 여전히 우수한 성능을 보인다.
이러한 이유로 업계는 두 아키텍처의 장점을 결합한 하이브리드 모델로 이동할 가능성을 점치고 있다.
출처 :
https://www.aitimes.com/news/articleView.html?idxno=208071
![[모바일 앱 동향] 매일경제](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)













![[중앙일보] 모바일 앱 동향](https://trend.mtlabs.org/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)